Core Concepts
Understanding the fundamental building blocks of DeepMod will help you create effective content moderation policies and interpret results accurately. This section explains the key concepts, terminology, and relationships that power our moderation system.
The Policy Hierarchy
Policy
A policy is the top-level container that defines your complete content moderation approach. Think of it as a comprehensive rulebook that determines what content is acceptable for your specific use case. Each policy contains all the rules, settings, and configuration needed to evaluate content consistently.
Policies can be created in three ways:
-
From Templates: Clone from 18+ pre-built, industry-specific policies (Social Media, E-commerce, Gaming, Healthcare, etc.) available at Policies → Templates
-
Automatic Generation: AI-extract policies from your existing documents (see Automatic Policy Generation)
-
Manual Creation: Build policies from scratch with complete control
Key characteristics of policies:
-
Name and Description: Human-readable identifiers that help you manage multiple policies
-
Friendly Identifier: A unique string that you can use for API calls instead of numeric IDs
-
Status: Either "Active" (can process content) or "Inactive" (disabled)
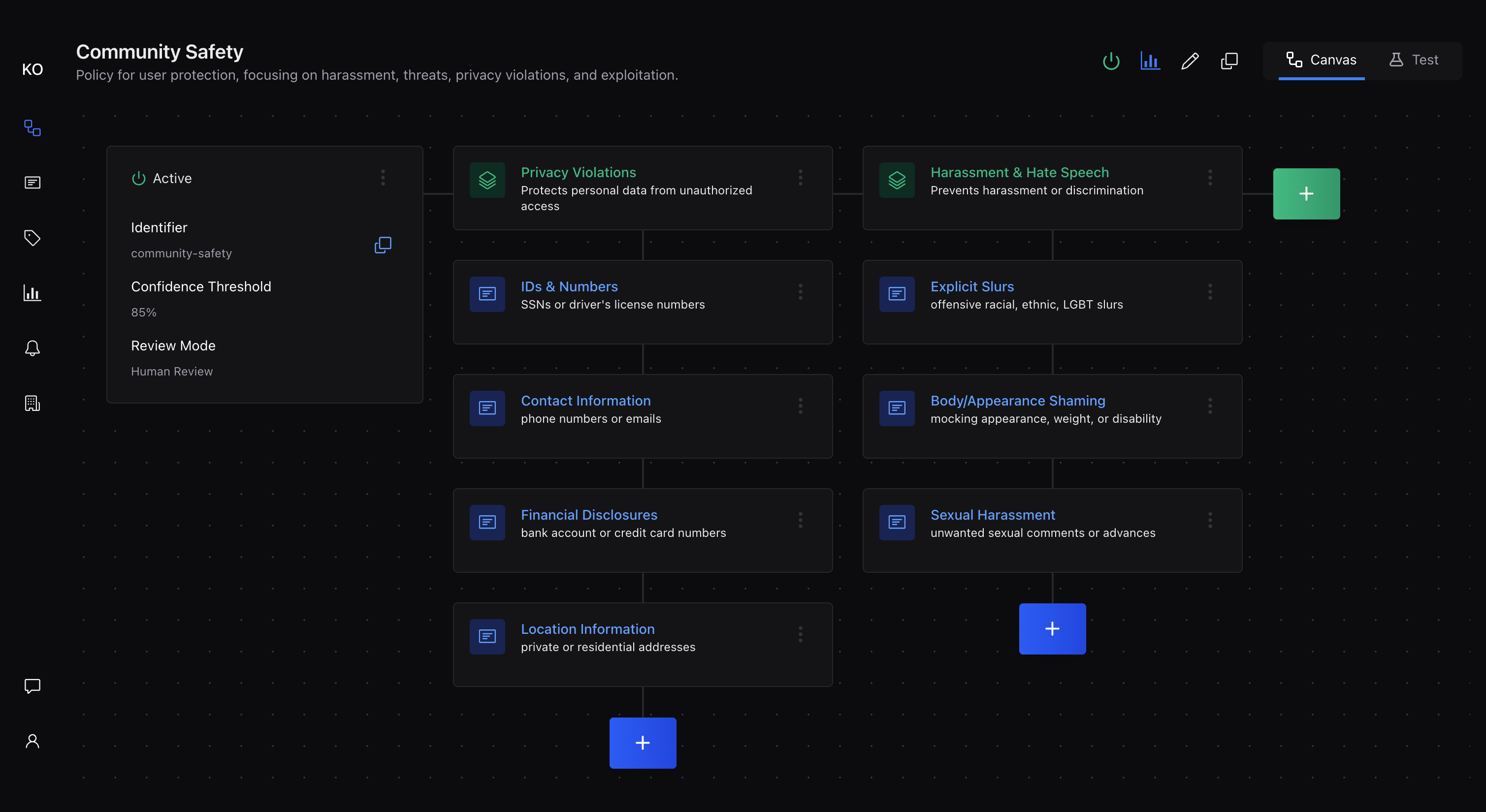
Rule Group
Rule groups provide logical organization within your policy, allowing you to categorize related rules for easier management and understanding. This organization helps both humans and the AI system process your moderation logic more effectively. Rule groups have names and descriptions, and you can create as many as needed to organize your policy clearly. The system evaluates all rule groups when processing content, so their organization is primarily for human management convenience.
Common rule group patterns:
-
Safety: Rules protecting users from harmful content like harassment, hate speech, or violence
-
Legal: Compliance-related rules covering copyright, privacy, regulatory requirements
-
Brand: Guidelines maintaining your brand voice, preventing competitor mentions, ensuring appropriate messaging
-
Spam: Detection rules for promotional content, repetitive posts, or suspicious patterns
Rule
Rules are the specific conditions that content must satisfy during moderation. Each rule represents a single, testable requirement written in natural language that both humans and AI can understand.
Rules have two main components:
-
Name: A short, descriptive title for the rule
-
Content: The detailed description of what the rule evaluates
Rule Examples
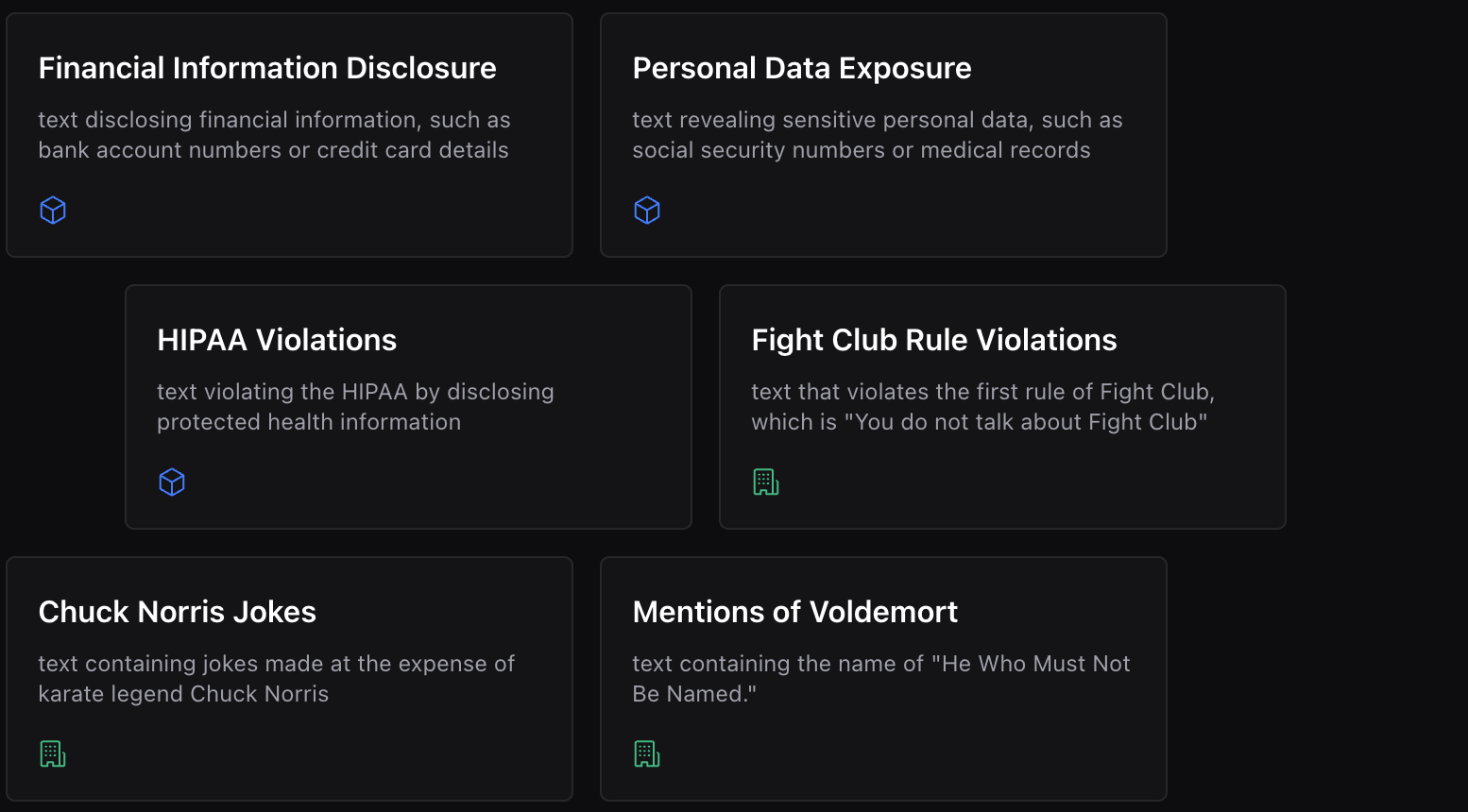
Effective rules are:
-
Specific: "Must not contain personally identifiable information" rather than "must be appropriate"
-
Actionable: Clear about what content should or shouldn't include
-
Focused: Each rule addresses one specific concern rather than multiple issues
-
Testable: You can easily determine whether content passes or fails the rule
Moderation Mechanics
Confidence Threshold
The confidence threshold is a crucial setting that determines how certain the AI must be before making a definitive decision. This numeric value (between 0.01 and 0.99, expressed as a percentage) acts as a sensitivity control for your entire policy.
How confidence works:
-
When the AI evaluates content against a rule, it provides a confidence score indicating how certain it is about the result
-
If the confidence score meets or exceeds your threshold, the system makes a definitive decision (Success or Failure)
-
If the confidence score falls below your threshold, the result becomes Ambiguous
Threshold tuning strategies:
-
Higher thresholds (80-90%): Fewer false positives, more ambiguous cases requiring human review
-
Lower thresholds (60-70%): More automated decisions, higher risk of false positives
-
Start conservative: Begin with higher thresholds and adjust based on real-world performance
Review Mode
Review mode determines what happens when the AI encounters ambiguous cases - content where rule violations might exist but confidence falls below your threshold. Choose your review mode based on your risk tolerance, content volume, and available human review capacity.
No Review Mode:
-
All decisions are made automatically based on confidence thresholds
-
Fastest processing with full automation
-
You will need to handle ambiguous results yourself (in your webhook handler)
Human Review Mode:
-
Ambiguous cases are flagged for human reviewers
-
Content evaluation pauses until a human makes the final decision
-
Higher accuracy for complex or nuanced content
-
Requires a dedicated QC team
-
Supports granular review: Reviewers can make rule-by-rule decisions rather than just an overall pass/fail
Content Limits
Deep Mod enforces content size limits to ensure consistent performance:
-
Maximum word count: 10,000 words per moderation request
-
Character restrictions: Control characters (except newlines and tabs) are not allowed
Content exceeding these limits will be rejected with an appropriate error message.
Policy Chaining
Policy chaining allows you to run a single piece of content through multiple policies sequentially, creating sophisticated multi-stage moderation workflows. Instead of applying just one policy, you can chain up to 10 policies together to create comprehensive evaluation processes.
How Policy Chaining Works
When you submit content for chained moderation:
-
Sequential Processing: Each policy in the chain is applied one after another
-
Early Termination: If any policy in the chain flags the content as a failure, the chain stops and remaining policies are marked as "abandoned"
-
Single Webhook: Instead of receiving multiple webhooks, you get one consolidated webhook with results from all executed policies
-
Unified Results: The final result reflects the outcome of the entire chain - success only if all policies pass
Chain Results
Each policy in a chain can have one of four results:
-
Success: Policy passed (content is acceptable)
-
Failure: Policy failed (content violates rules) - chain stops here
-
Ambiguous: Policy result unclear - may pause for human review if enabled
-
Abandoned: Policy was not executed because an earlier policy failed
Example Use Cases
Content Progression Pipeline
1. Safety Policy → 2. Legal Compliance → 3. Brand Guidelines
Content must pass basic safety checks before advancing to legal review, then finally brand compliance.
Tiered Moderation
1. Basic Spam Detection → 2. Advanced Content Analysis → 3. Contextual Review
Quick spam filtering first, then deeper analysis only for content that passes initial screening.
Regional Compliance
1. Global Standards → 2. Regional Laws → 3. Local Guidelines
Apply universal standards, then region-specific requirements, then local community guidelines.
Benefits of Chaining
-
Efficiency: Stop processing as soon as content fails any stage
-
Organization: Separate concerns into focused, single-purpose policies
-
Reusability: Mix and match existing policies for different workflows
-
Clarity: Each policy addresses one specific area of concern
Review in Policy Chains
When using policy chaining with human review enabled:
-
Chain Pauses: If any policy returns an ambiguous result and requires review, the entire chain pauses
-
Resume on Review: After human review completes, the chain continues with the next policy
-
Failed Reviews: If a human reviewer marks an ambiguous result as a failure, the chain stops and remaining policies are abandonedResult Types and Outcomes
Every piece of content processed by Deep Mod receives one of four possible outcomes, each with specific meaning and implications for your content workflow.
Success
Success indicates that content has passed all applicable rules within your confidence thresholds. This means:
-
No rules were violated with sufficient confidence
-
Content can proceed through your normal workflow
-
No human intervention is required (regardless of review mode)
Failure
Failure means content has violated one or more rules with confidence at or above your threshold. This indicates:
-
Clear policy violations that require action
-
Content should be blocked, rejected, or flagged according to your workflow
-
High confidence in the decision means minimal risk of false positives
Ambiguous
Ambiguous results occur when potential rule violations exist but confidence levels fall below your threshold. This represents:
-
Borderline content that requires human judgment
-
Cases where the AI isn't certain enough to make an automatic decision
Abandoned
Abandoned results occur exclusively in policy chaining scenarios. This indicates:
-
The policy was not executed because an earlier policy in the chain failed
-
No evaluation was performed against this policy's rules
-
No credits are consumed for abandoned policies
-
Credits and Billing
Deep Mod uses a credit-based billing system that reflects the actual cost of processing your content. Understanding credits helps you manage costs effectively.
What is a Credit?
A credit is the billing unit in Deep Mod. Credits account for both the fixed overhead of each moderation request and the variable cost based on content complexity.
Credit Calculation
Each moderation run is billed using this formula:
Credits = 100 + (Word Units x Rules)Where:
-
100 is the base charge per moderation run (covers fixed processing overhead)
-
Word Units = content word count divided by 100, rounded up
-
Rules = number of rules in the policy
Example: Moderating 500 words against a policy with 10 rules:
Credits = 100 + (5 x 10) = 150 creditsWhy Base Charge + Variable?
The base charge exists because every moderation run has fixed processing costs regardless of content size. The variable portion scales with the complexity of your moderation needs (longer content and more rules cost more).
Policy Chaining and Credits
When you chain multiple policies, each policy creates a separate moderation run with its own credit calculation:
-
500-word content through 2 policies (10 rules each) = 150 + 150 = 300 credits
-
500-word content through 1 policy (20 rules) = 100 + (5 x 20) = 200 credits
Combining rules into fewer policies can be more credit-efficient than chaining many small policies.
Note: Abandoned policies in a chain do not consume credits since no evaluation is performed.
Moderation Runs
A moderation run represents a complete evaluation of content against a single policy, creating a permanent record of the decision process and results. Each moderation run consumes credits based on the formula above.
Run Components
Each moderation run contains:
-
Content: The original text that was evaluated
-
Policy Reference: Which policy and rules were applied
-
Moderation Mode: Which mode was used (moderate or test)
-
Overall Result: Success, Failure, Ambiguous, or Abandoned outcome
-
Detailed Results: Results for each rule group and individual rule evaluation
-
Confidence Scores: Both individual rule confidence and overall confidence
-
Credit Count: The number of credits consumed by this run
-
Review Status: Whether the run is pending review, reviewed, or not applicable
-
Webhook Status: Delivery status, attempts, and timestamp
Run Lifecycle
-
Submission: Content is submitted for moderation via API or dashboard
-
Credit Check: System verifies organization has sufficient credits
-
Processing: AI evaluates content against all policy rules
-
Decision: System determines Success, Failure, or Ambiguous based on confidence threshold
-
Recording: Run details and credit consumption are stored
-
Notification: Results are sent via webhook (if configured)
-
Review (if applicable): Human reviewers process ambiguous cases (no additional credits)
-
Review (if applicable): Human reviewers process ambiguous cases
Metadata and Tags
Metadata and tags provide essential context and organization capabilities for your moderation runs.
Metadata
Metadata is custom key-value data that you attach to moderation requests to provide context and enable downstream processing. Common metadata includes:
{
"userId": "user_12345",
"postId": "post_67890",
"source": "comment",
"region": "europe",
"contentType": "user_generated"
}Metadata benefits:
-
Context Preservation: Maintain links between moderated content and your application data
-
Downstream Processing: Use metadata in your webhook handlers to route or process results appropriately
-
Analytics: Filter and analyze moderation patterns by custom dimensions
-
Audit Trails: Maintain complete records for compliance and troubleshooting
Tags
Tags are predefined labels that you can attach to moderation runs for categorization and filtering. Unlike metadata, tags must be created in your organization before use. Tags can be attached when submitting content for moderation via the API.
Tag use cases:
-
Content Categorization: "product_review", "user_comment", "forum_post"
-
Regional Filtering: "us", "europe", "asia_pacific"
-
Priority Levels: "high_priority", "standard", "low_priority"
-
Source Systems: "mobile_app", "web_portal", "api_integration"
Benefits of tags:
-
Queue Filtering: View specific subsets of moderation runs in your dashboard
-
Analytics Segmentation: Compare moderation patterns across different content types or sources
-
Performance Analysis: Identify which content types require more human review or policy refinement
Webhooks
Webhooks provide real-time notifications when moderation is complete or when moderation fails, enabling seamless integration between Deep Mod and your applications.
Webhook Functionality
When content moderation finishes, Deep Mod sends an HTTP POST request to your configured webhook URL containing:
-
Complete moderation results (Success, Failure, Ambiguous, or Abandoned)
-
Detailed rule results and confidence scores
-
Attached metadata
-
Run identification for tracking and deduplication
Webhook Delivery Tracking
Deep Mod tracks webhook delivery status for each moderation run:
-
Delivery Status: Pending, delivered, or failed
-
Attempt Count: Number of delivery attempts made
-
Delivery Timestamp: When the webhook was successfully delivered
Integration Requirements
-
Endpoint Accessibility: Your webhook URL must be publicly accessible and accept POST requests
-
JSON Processing: Handle JSON payloads containing moderation results
-
Response Codes: Return 2xx status codes to confirm successful receipt
-
Idempotency: Handle duplicate deliveries gracefully using run IDs
-
Security (Recommended): Verify webhook signatures using your organization's client secret
Webhooks are configured at the organization level and provide the primary mechanism for integrating moderation results into your content workflows..
Understanding Relationships
These core concepts work together to create a flexible, powerful moderation system:
Policy → Rule Groups → Rules creates the hierarchical structure that organizes your moderation logic clearly and maintainably.
Confidence Threshold + Review Mode determines how the system handles uncertain cases, balancing automation with human oversight.
Success/Failure/Ambiguous + Moderation Runs provide detailed, auditable records of every moderation decision with complete reasoning.
Metadata + Tags + Webhooks enable rich integration possibilities, allowing you to categorize, route, and process moderation results according to your specific business requirements.
Understanding these relationships helps you design effective policies, interpret results accurately, and build robust integrations that scale with your content volume and complexity.
Subscription Limits
Your subscription tier determines certain limits on your usage:
-
Monthly Credits: Total credits available per billing period
-
API Requests Per Minute: Rate limit for API calls
-
Max Rules Per Policy: Maximum number of rules allowed in a single policy
-
Max Batch Size: Maximum number of policies in a single chained request
Check your subscription details in the dashboard to see your current limits.
Understanding Relationships
These core concepts work together to create a flexible, powerful moderation system:
Policy → Rule Groups → Rules creates the hierarchical structure that organizes your moderation logic clearly and maintainably.
Moderation Modes determine how content is processed and what outputs you receive.
Confidence Threshold + Review Mode determines how the system handles uncertain cases, balancing automation with human oversight.
Success/Failure/Ambiguous/Abandoned + Moderation Runs provide detailed, auditable records of every moderation decision with complete reasoning.
Metadata + Tags + Webhooks enable rich integration possibilities, allowing you to categorize, route, and process moderation results according to your specific business requirements.
Understanding these relationships helps you design effective policies, interpret results accurately, and build robust integrations that scale with your content volume and complexity.
What's Next
With these core concepts understood, you're ready to explore more advanced topics:
-
Using the Dashboard - Navigate the interface to manage policies and review results
-
Running Moderation - Advanced techniques for scaling and optimizing your moderation
-
Interpreting Results - Deep dive into understanding and acting on moderation outcomes
-
Policy Authoring Best Practices - Advanced strategies for creating robust, maintainable policies
These fundamentals provide the foundation for everything else in DeepMod - from creating your first policy to scaling content moderation across complex, high-volume applications.
Questions about core concepts? These fundamentals are essential for effective moderation - contact our support team if you need clarification on any of these concepts.