Interpreting Results
Understanding moderation results is crucial for optimizing your policies, making data-driven improvements, and building effective content workflows. This section explains how to read, analyze, and act on the detailed feedback provided by Deep Mod.
Understanding Result Structure
Every moderation result provides a comprehensive breakdown of how your content was evaluated, giving you complete visibility into the decision-making process.
Overall Result Components
Primary Outcome: Every result includes one of four possible decisions:
-
success: Content passed all rules within confidence thresholds -
failure: Content violated one or more rules with sufficient confidence -
ambiguous: Potential violations detected but confidence below threshold -
abandoned: Content was not processed (used in batch operations when a prior policy in the chain failed)
Run Status: Separate from the result, each moderation run has a status:
-
pendingReview: Result requires human review before finalization -
completed: Result is final (either reviewed or no review required)
Average Confidence: The overall confidence score for the entire policy evaluation, calculated by averaging confidence scores from all rule groups.
Hierarchical Breakdown
Results follow a hierarchical structure that mirrors your policy organization. This structure allows you to understand not just what happened, but exactly where in your policy the decision was made.
→ Policy Level: The top-level result with overall outcome and summary
→ Rule Group Level: Results for each rule group (Safety, Legal, Brand, etc.)
→ Individual Rule Level: Detailed results for each rule within the group
This structure allows you to understand not just what happened, but exactly where in your policy the decision was made.
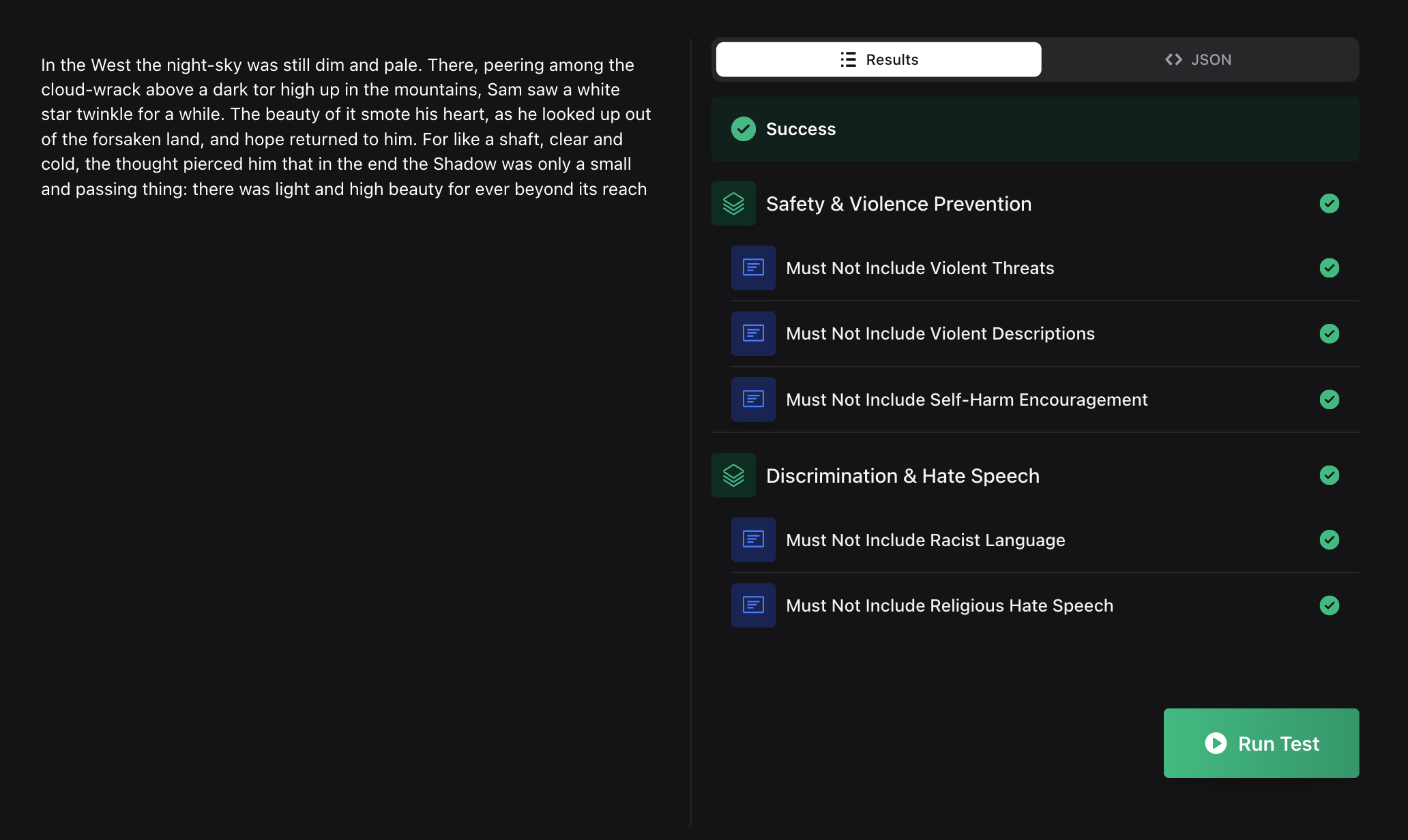
Detailed Result Example
Here's what a complete moderation result looks like:
{
"policy": "community-guidelines-policy",
"result": "failure",
"averageConfidence": 0.87,
"ruleGroupResults": [
{
"name": "Safety",
"result": "failure",
"averageConfidence": 0.91,
"ruleResults": [
{
"ruleId": 42,
"condition": "must not include threatening language",
"result": "failure",
"averageConfidence": 0.91,
"matchedContent": [
{
"content": "threatening phrase detected",
"confidence": 0.91
}
]
}
]
},
{
"name": "Brand",
"result": "success",
"averageConfidence": 0.83,
"ruleResults": [...]
}
]
}Result Fields After Human Review
When a moderation result has been reviewed, additional fields are included:
{
"policy": "community-guidelines-policy",
"result": "failure",
"averageConfidence": 0.87,
"reviewed": true,
"reviewNote": "Reviewer determined content contains implicit threat",
"reviewItems": [
{
"ruleId": 42,
"ruleName": "must not include threatening language",
"decision": "failure"
}
],
"ruleGroupResults": [...]
}Confidence Scores Explained
Confidence scores are fundamental to understanding and tuning your moderation system. They represent how certain the AI is about detecting the presence or absence of rule violations.
What Confidence Represents
Range: Confidence scores are normalized to a range between 0.01 and 0.99 (1% to 99%)
Meaning: Higher scores indicate greater certainty about whether the rule's topic is present or absent in the content.
-
0.90+ (90%+): Very high confidence - AI is very certain about its detection
-
0.70-0.89 (70-89%): High confidence - AI is confident about its detection
-
0.50-0.69 (50-69%): Medium confidence - AI has moderate certainty
-
0.30-0.49 (30-49%): Low confidence - AI has low certainty
-
Below 0.30 (30%): Very low confidence - AI is uncertain about its detection
Important: Confidence measures certainty about detection, not about whether content is "good" or "bad." It applies equally to all outcomes.
Confidence Hierarchy
Rule-Level Confidence: Each individual rule evaluation receives a confidence score representing how certain the AI is about whether the rule's topic is present in the content.
Group-Level Confidence: Calculated by averaging the confidence scores of all rules within that group.
Overall Confidence: The final confidence score representing the certainty of the entire policy decision, calculated by averaging all group-level confidences.
How Results Are Classified
Your policy's confidence threshold determines how detections are classified into results. The classification logic considers both whether a topic is detected (present) and the confidence of that detection:
|
Topic Detected |
Confidence vs Threshold |
Result |
|---|---|---|
|
Yes ( |
At or above threshold |
|
|
Yes ( |
Below threshold |
|
|
No ( |
Below threshold |
|
|
No ( |
At or above threshold |
|
Key insight: Ambiguous results occur in two scenarios:
-
A violation was detected but with low confidence
-
No violation was detected but the AI wasn't confident in that assessment
Using Confidence Thresholds
Threshold Strategy:
-
Conservative (80-90%): Fewer false positives, more ambiguous results requiring review
-
Balanced (70-80%): Good balance of automation and accuracy
-
Aggressive (60-70%): More automation, higher false positive risk
Review Mode Behavior:
|
Review Mode |
Ambiguous Handling |
|---|---|
|
|
Run status set to |
|
|
Run status set to |
Analyzing Patterns and Trends
Effective interpretation goes beyond individual results to identify patterns across your content moderation.
Common Analysis Approaches
Volume Analysis: Track the distribution of success, failure, and ambiguous results over time to understand overall content quality trends.
Confidence Distribution: Monitor how confidence scores cluster to identify opportunities for threshold adjustment.
Rule Performance: Analyze which rules are most frequently triggered to identify common content issues or overly broad rules.
Source Segmentation: Use metadata and tags to compare moderation patterns across different content sources, user types, or geographic regions.
Key Metrics to Monitor
False Positive Rate: Content incorrectly flagged as violations
-
Track by monitoring
successresults that users appeal or complain about -
Indicates rules may be too broad or thresholds too low
False Negative Rate: Violations missed by automated moderation
-
Monitor through human review overturn rates
-
Suggests rules may be too narrow or thresholds too high
Ambiguous Rate: Percentage of content requiring human review
-
High rates may indicate poorly tuned thresholds
-
Very low rates might suggest missed edge cases
Confidence Distribution: How confidence scores cluster around your threshold
-
Many scores just below threshold suggest threshold adjustment opportunities
-
Bimodal distributions indicate clear separation between good and bad content
Practical Optimization Strategies
Threshold Tuning
Identify Threshold Opportunities:
-
Review content with confidence scores within 10% of your threshold
-
Look for patterns in false positives and false negatives
-
Consider separate thresholds for different rule groups
Tuning Approach:
-
Collect 50-100 recent results across different content types
-
Categorize outcomes as correct or incorrect
-
Plot confidence scores against correctness
-
Identify optimal threshold that minimizes total errors
Example Analysis:
Current threshold: 75%
Content scoring 70-74%: 80% are actually violations (consider lowering threshold)
Content scoring 76-80%: 95% are correctly identified (threshold working well)
Content scoring 81-85%: 98% accuracy (high confidence zone)Rule Refinement
Overactive Rules: Rules that frequently trigger with low accuracy
-
Symptoms: High trigger rate, many false positives, user complaints
-
Solutions: Add exceptions, increase specificity, adjust rule wording
-
Example: "No negative language" → "No personal attacks or threats"
Underactive Rules: Rules that rarely trigger but miss obvious violations
-
Symptoms: Low trigger rate, violations slip through, user reports
-
Solutions: Broaden scope, add variations, decrease specificity
-
Example: "No spam" → "No repetitive promotional content or excessive links"
Conflicting Rules: Rules that create ambiguous or contradictory results
-
Symptoms: High ambiguous rate for specific content types
-
Solutions: Clarify rule boundaries, add priority ordering, merge related rules
Content-Specific Adjustments
Content Type Patterns: Different content types may need different handling
-
Product reviews vs. forum discussions vs. customer support
-
Adjust thresholds or rules based on content context
-
Use metadata to track performance by content type
User Behavior Analysis: User patterns can inform policy adjustments
-
New users vs. established community members
-
Content creator vs. consumer patterns
-
Trust level or reputation score integration
Quality Tuning Playbook
Follow this systematic approach to optimize your moderation performance:
Step 1: Data Collection
-
Sample Recent Results: Collect 50-100 recent moderation runs across different content types and sources
-
Categorize Outcomes: Mark each result as correct/incorrect based on manual review
-
Document Context: Note content type, source, user context, and any special circumstances
Step 2: Pattern Analysis
-
Calculate Error Rates: Determine false positive and false negative rates overall and by rule group
-
Confidence Analysis: Plot confidence scores against correctness to identify threshold issues
-
Rule Performance: Identify rules with high error rates or unusual triggering patterns
Step 3: Targeted Improvements
-
Rule Adjustments: Modify or replace rules with high error rates
-
Threshold Tuning: Adjust confidence thresholds based on confidence distribution analysis
-
Policy Structure: Consider splitting or merging rule groups based on performance patterns
Step 4: Validation Testing
-
Re-test Samples: Run the same content samples through updated policies
-
Measure Improvement: Compare error rates before and after changes
-
Monitor Production: Watch for improvement in live moderation metrics
Step 5: Ongoing Monitoring
-
Trend Analysis: Look for changes in content patterns or policy performance
-
Seasonal Adjustments: Account for seasonal content variations or platform changes
-
Policy Evolution: Update policies as community standards and business needs evolve
Advanced Result Analysis
Matched Content Analysis
The matchedContent array in rule results shows exactly what text triggered each rule:
"matchedContent": [
{
"content": "specific triggering phrase",
"confidence": 0.87
}
]Note: Matched content snippets are limited to 5 words or fewer.
Use Cases:
-
False Positive Investigation: Understand why benign content was flagged
-
Rule Improvement: Identify common patterns that need exception handling
-
Training Data: Collect examples for policy refinement discussions
Multi-Rule Interactions
Analyze how multiple rules interact within rule groups:
-
Reinforcing Rules: Multiple rules flagging the same content increases overall confidence
-
Conflicting Signals: Some rules triggering while others don't can indicate edge cases
Confidence Clustering
Look for patterns in confidence score distributions:
-
High Confidence Clusters (85%+): Clear-cut cases that can guide rule optimization
-
Medium Confidence Clusters (60-75%): Potential threshold adjustment opportunities
-
Low Confidence Clusters (Below 50%): May indicate irrelevant rules or content
Integration with Business Logic
Risk-Based Processing
function processBasedOnRisk(result) {
const { result: outcome, averageConfidence, ruleGroupResults } = result;
// High-risk violations (safety, legal)
const highRiskViolations = ruleGroupResults.filter(
(group) => ['Safety', 'Legal'].includes(group.name) && group.result === 'failure'
);
if (highRiskViolations.length > 0) {
return 'immediate_block';
}
// Medium-risk with high confidence
if (outcome === 'failure' && averageConfidence > 0.8) {
return 'block_with_appeal';
}
// Low confidence failures
if (outcome === 'failure' && averageConfidence < 0.6) {
return 'flag_for_review';
}
// Ambiguous results
if (outcome === 'ambiguous') {
return 'flag_for_review';
}
return 'approve';
}
def process_based_on_risk(result):
outcome = result['result']
average_confidence = result['averageConfidence']
rule_group_results = result['ruleGroupResults']
# High-risk violations (safety, legal)
high_risk_violations = [
group for group in rule_group_results
if group['name'] in ['Safety', 'Legal'] and group['result'] == 'failure'
]
if high_risk_violations:
return 'immediate_block'
# Medium-risk with high confidence
if outcome == 'failure' and average_confidence > 0.8:
return 'block_with_appeal'
# Low confidence failures
if outcome == 'failure' and average_confidence < 0.6:
return 'flag_for_review'
# Ambiguous results
if outcome == 'ambiguous':
return 'flag_for_review'
return 'approve'<?php
function processBasedOnRisk($result) {
$outcome = $result['result'];
$averageConfidence = $result['averageConfidence'];
$ruleGroupResults = $result['ruleGroupResults'];
// High-risk violations (safety, legal)
$highRiskViolations = array_filter($ruleGroupResults, function($group) {
return in_array($group['name'], ['Safety', 'Legal']) &&
$group['result'] === 'failure';
});
if (count($highRiskViolations) > 0) {
return 'immediate_block';
}
// Medium-risk with high confidence
if ($outcome === 'failure' && $averageConfidence > 0.8) {
return 'block_with_appeal';
}
// Low confidence failures
if ($outcome === 'failure' && $averageConfidence < 0.6) {
return 'flag_for_review';
}
// Ambiguous results
if ($outcome === 'ambiguous') {
return 'flag_for_review';
}
return 'approve';
}
?>def process_based_on_risk(result)
outcome = result['result']
average_confidence = result['averageConfidence']
rule_group_results = result['ruleGroupResults']
# High-risk violations (safety, legal)
high_risk_violations = rule_group_results.select do |group|
['Safety', 'Legal'].include?(group['name']) && group['result'] == 'failure'
end
if high_risk_violations.any?
return 'immediate_block'
end
# Medium-risk with high confidence
if outcome == 'failure' && average_confidence > 0.8
return 'block_with_appeal'
end
# Low confidence failures
if outcome == 'failure' && average_confidence < 0.6
return 'flag_for_review'
end
# Ambiguous results
if outcome == 'ambiguous'
return 'flag_for_review'
end
'approve'
endDynamic Threshold Adjustment
function getAdjustedThreshold(contentMetadata, baseThreshold) {
let threshold = baseThreshold;
// Adjust for content sensitivity
if (contentMetadata.isPublic) threshold += 0.1;
if (contentMetadata.hasMinors) threshold += 0.15;
// Adjust for user reputation
if (contentMetadata.userTrustScore > 0.8) threshold -= 0.05;
if (contentMetadata.userTrustScore < 0.3) threshold += 0.1;
return Math.min(0.95, Math.max(0.5, threshold));
}def get_adjusted_threshold(content_metadata, base_threshold):
threshold = base_threshold
# Adjust for content sensitivity
if content_metadata.get('isPublic'):
threshold += 0.1
if content_metadata.get('hasMinors'):
threshold += 0.15
# Adjust for user reputation
user_trust_score = content_metadata.get('userTrustScore', 0.5)
if user_trust_score > 0.8:
threshold -= 0.05
if user_trust_score < 0.3:
threshold += 0.1
return min(0.95, max(0.5, threshold))<?php
function getAdjustedThreshold($contentMetadata, $baseThreshold) {
$threshold = $baseThreshold;
// Adjust for content sensitivity
if (!empty($contentMetadata['isPublic'])) {
$threshold += 0.1;
}
if (!empty($contentMetadata['hasMinors'])) {
$threshold += 0.15;
}
// Adjust for user reputation
$userTrustScore = $contentMetadata['userTrustScore'] ?? 0.5;
if ($userTrustScore > 0.8) {
$threshold -= 0.05;
}
if ($userTrustScore < 0.3) {
$threshold += 0.1;
}
return min(0.95, max(0.5, $threshold));
}
?>def get_adjusted_threshold(content_metadata, base_threshold)
threshold = base_threshold
# Adjust for content sensitivity
threshold += 0.1 if content_metadata['isPublic']
threshold += 0.15 if content_metadata['hasMinors']
# Adjust for user reputation
user_trust_score = content_metadata['userTrustScore'] || 0.5
threshold -= 0.05 if user_trust_score > 0.8
threshold += 0.1 if user_trust_score < 0.3
[0.95, [0.5, threshold].max].min
end
What's Next
With solid result interpretation skills, explore these advanced topics:
-
Human Review Workflows - Advanced strategies for managing human oversight efficiently
-
Policy Authoring Best Practices - Expert techniques for creating robust, maintainable policies
-
Troubleshooting - Common issues and solutions for result interpretation challenges
Effective result interpretation transforms raw moderation data into actionable insights that continuously improve your content governance and user experience.
Need help interpreting specific results? Contact our support team with examples of confusing or unexpected outcomes for personalized guidance on optimization strategies.